AWS Free Tier
This is a short story about how EFS almost killed our Kubernetes cluster, and how you can avoid ending up in the same pickle — even if you don’t use EFS.
Published July 24 2019
This is a short story about how EFS almost killed our Kubernetes cluster, and how you can avoid ending up in the same pickle — even if you don’t use EFS.
Published July 24 2019
Fall 2018: A colleague and I set up a Kubernetes cluster on AWS. We went to production without much fuss, and things worked as expected. Fast forward 5-6 months, and the situation turned upside down overnight.
Spring 2019: After running without problems for nearly half a year, our Kubernetes cluster started to have issues. Well, at least the nodes. The first symptom we observed was that many of our pods had a short lifespan, with frequent restarts. After this went on for a while, we occasionally got a troublesome node that Kubernetes itself couldn’t manage to fix.
After inspecting logs from our apps and (what we assumed were) relevant metrics, we couldn’t see any obvious reason for the restarts. Since Kubernetes still struggled to get control over certain nodes, we were forced on multiple occasions to literally go into the EC2 console and “physically” shut down certain nodes. Kubernetes would bring up a new node, which after a short time would get stuck again. We had a deeper problem.
A bit of digging showed that the triggering symptom was that pods after a short time started to take unusually long to respond to their health check. This caused Kubernetes to decide to bring the pods down and then back up. This played out over and over, and after enough of these loops, the node stopped responding to the master’s commands. What on earth was going on?
One day, for the nth time, I was looking at the output from kubectl get pods,
with tears in my eyes, when it hit me — all the pods that had problems used disk
from EFS. Many of the systems we run in this cluster are older and use disk.
As part of the migration to Kubernetes, we concluded that EFS would be good
enough for this disk access (which mostly consisted of config files). It
turned out to be almost true.
AWS sells EFS with the following text among others:
AWS documentationThroughput and IOPS scale as a file system grows and can burst to higher throughput levels for short periods of time to support the unpredictable performance needs of file workloads. For the most demanding workloads, Amazon EFS can support performance over 10 GB/sec and up to 500,000 IOPS.
Sounds promising, right? But what else does AWS say about throughput?
AWS documentationAmazon EFS Bursting Throughput (Default)In the default Bursting Throughput mode, there are no charges for bandwidth or requests and you get a baseline rate of 50 KB/s per GB of throughput included with the price of storage.
Our use of EFS mainly consisted of reading some config files. Very little writing. Our data amounts were well below 1GB. So we were guaranteed a whole 0.05 Mbit/s transfer rate.
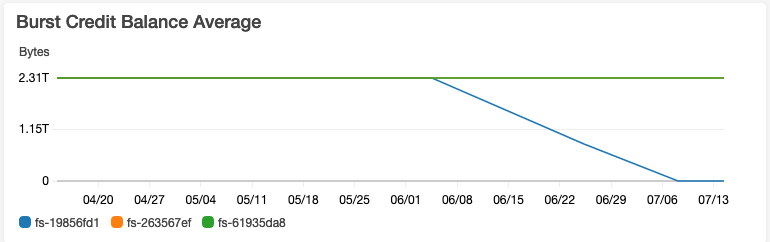
When we then knew that all the pods that had problems used the same EFS share, and the transfer from EFS overall was throttled to 0.05 Mbit/s, it was quite obvious where the problem lay. But why did it take 6 months before this became an issue?
Many AWS services are so-called “burstable”. That is, they have some kind of baseline performance that you can exceed for a given time period each day. This system is based on credits — as long as you stay under the burst limit, you earn credits per hour, and when you go over you use up this credit balance.
EFS has burstable throughput, as explained in dedicated documentation. An immediate challenge here is that AWS assumes that the throughput need scales linearly with the amount of data you store on EFS. For data that is “read mostly” this does not fit very well. But still, one can ask — why did it take 6 months before we ran into problems with this?
The concrete problem we ran into is so common that AWS has a dedicated FAQ page for it: What’s up with EFS burst credits? EFS allows you to save up 2.1TB of burst traffic per TB you have on a share, minimum 2.1TB. When you create a new share you start with a full credit balance.
Here’s what the problem looked like for us:
So:
Thus, a number of pods failed their health checks and were restarted by Kubernetes, over and over. This worsened the problem, as some of the services read quite a bit of data from disk during startup. D’OH!
So what should you, dear reader, take away from this little anecdote? We learned several things from this blunder:
(We already know about “avoid disk in cloud solutions”, but all software is not always in an ideal state).
When summarized like this, it might seem idiotic of us not to check how a service works before using it. That is valid criticism, but given the amount of external services and libraries we use every day, it’s probably utopian to think we can have 100% insight into every detail for each of them. My hope with this post is that you’ll be a little more careful next time you review terms for a cloud product you haven’t used before.
Regardless of not knowing about this system, you might wonder why we didn’t discover it through metrics or alarms? We have plenty of AWS metrics in Datadog, but apparently so many that we can’t actively monitor all of them. In addition, our alarms are still manually defined, rather than reporting general anomalies — “WARNING! EFS Credits dropping sharply.” These are challenges we can fix after the fact, but surely we have more such blind spots we don’t yet know.
It’s tempting to call this error a case of the “AWS free tier trap,” a trap that manifests itself in one of two ways. One is that things stop working, like in our case. The other is that your operational costs suddenly skyrocket. Neither is particularly fun, but unfortunately both are quite common. How do you avoid them? Read the terms, and monitor AWS’s own metrics, especially the credit balance, where relevant. And cross your fingers that you manage to keep track of everything.

